Building an Open-Source LLM Chatbot with RAG Techniques
Written on
Introduction to LLM Chatbots
In this guide, we will create a Local LLM chatbot using Retrieval-Augmented Generation (RAG) to answer specific queries based on a user manual for a washing machine. LLMs are exceptional at encoding vast knowledge into their parameters but have notable limitations. They often possess outdated knowledge and may produce incorrect information when asked specific questions. By applying the RAG method, we can enhance the capabilities of pre-trained LLMs by providing them with relevant contextual information during the query process.
Our implementation will leverage Google’s LLM, Gemma, alongside the Hugging Face transformers library, LangChain, and the Faiss vector database. Below is a visual representation of the RAG pipeline, which we will construct step-by-step.
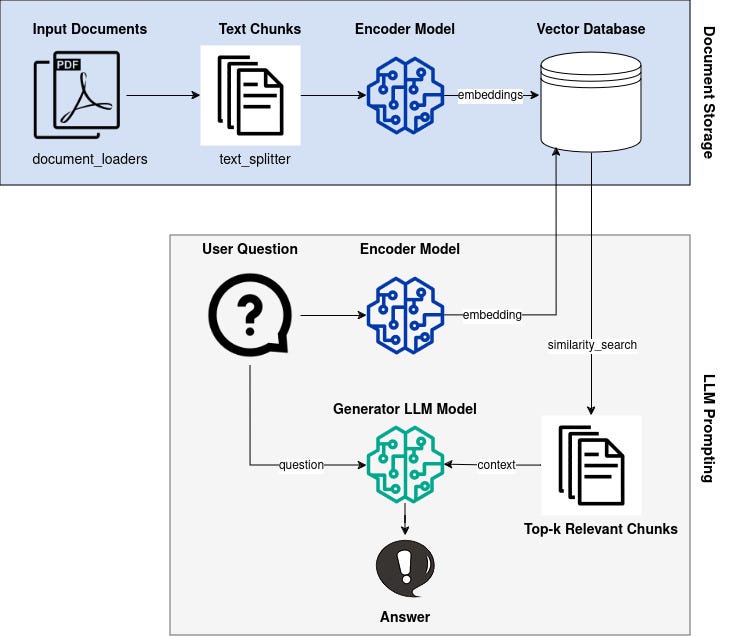
Understanding RAG: Retrieval-Augmented Generation
Retrieval-Augmented Generation (RAG) is a concept introduced in a 2020 paper by researchers from Facebook AI Research, University College London, and New York University. The essence of RAG is straightforward:
- We begin with a knowledge base, which can consist of various text documents. These documents are transformed into dense vector representations using an encoder model.
- A user query is also converted into an embedding vector using the same encoder.
- We then identify similar vectors to the user query from our existing knowledge base using a similarity metric.
- The relevant documents retrieved provide additional context to feed into an LLM, enabling it to generate accurate responses.
Next, we will implement the generator component of our RAG pipeline.
Generator Component: Implementing the LLM Model
The generator serves as an LLM that processes input text and generates new text as output. The original RAG paper utilized BART-large for this purpose. However, a plethora of open-source LLMs are now available. For our chatbot, I selected Google’s newly launched model, Gemma-2b-it, which is tailored for conversational data and is lightweight enough to run on local machines.
To utilize Gemma, we must adhere to Google’s usage policies. By verifying our Hugging Face credentials, we can supply our access token to the transformers API.
# Create a .env file with your Hugging Face access token
ACCESS_TOKEN=<your hugging face access token>
We will now initialize the Gemma LLM model.
!pip install torch transformers bitsandbytes accelerate
import os
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from dotenv import load_dotenv
load_dotenv()
ACCESS_TOKEN = os.getenv("ACCESS_TOKEN")
model_id = "google/gemma-2b-it"
tokenizer = AutoTokenizer.from_pretrained(model_id, token=ACCESS_TOKEN)
quantization_config = BitsAndBytesConfig(load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16)
model = AutoModelForCausalLM.from_pretrained(model_id,
device_map="auto",
quantization_config=quantization_config,
token=ACCESS_TOKEN)
model.eval()
device = 'cuda' if torch.cuda.is_available() else 'cpu'
To optimize memory usage, we will implement 4-bit quantization, which necessitates an Nvidia GPU.
def generate(question: str, context: str):
if not context:
prompt = f"Provide a detailed answer to the following question: {question}"else:
prompt = f"Using the context provided, answer the following question: {question}. Context: {context}"
chat = [{"role": "user", "content": prompt}]
formatted_prompt = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
inputs = tokenizer.encode(formatted_prompt, add_special_tokens=False, return_tensors="pt").to(device)
with torch.no_grad():
outputs = model.generate(input_ids=inputs, max_new_tokens=250, do_sample=False)
response = tokenizer.decode(outputs[0], skip_special_tokens=False).replace("<eos>", "")
return response
This function allows us to generate answers based on user queries, with or without additional context.
The first video demonstrates building a chatbot with advanced RAG techniques using open-source models and frameworks.
Retriever Component: Encoder Model and Similarity Search
The encoder model’s role is to convert text into dense vector representations that encapsulate the underlying information. The original RAG paper utilized a BERT encoder, but we have the flexibility to choose any suitable encoder. For this tutorial, I opted for the "all-MiniLM-L12-v2" model, which is compact yet efficient.
from langchain_community.embeddings import HuggingFaceEmbeddings
encoder = HuggingFaceEmbeddings(model_name='sentence-transformers/all-MiniLM-L12-v2', model_kwargs={'device': "cpu"})
We can test the encoder's functionality with a sample query.
embeddings = encoder.embed_query("How are you?")
print(len(embeddings)) # Should output 384
Next, we will conduct a similarity search using cosine similarity.
import numpy as np
q = encoder.embed_query("What is an apple?")
z1 = encoder.embed_query("An apple is a round, edible fruit produced by an apple tree.")
z2 = encoder.embed_query("The cat is a domesticated species.")
similarity1 = np.dot(q, z1) / (np.linalg.norm(q) * np.linalg.norm(z1))
similarity2 = np.dot(q, z2) / (np.linalg.norm(q) * np.linalg.norm(z2))
print(similarity1) # Expect a higher value for z1
print(similarity2)
The cosine similarity ranges from -1 to +1, indicating how closely related the vectors are.
Document Loader and Text Splitter
Now, we will build our knowledge base using multiple PDF documents. Since each PDF can be lengthy, we will segment them into smaller, manageable chunks for processing.
!pip install pypdf tiktoken langchain sentence-transformers
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
loaders = [
PyPDFLoader("/path/to/pdf/file1.pdf"),
PyPDFLoader("/path/to/pdf/file2.pdf"),
]
pages = [loader.load() for loader in loaders]
text_splitter = RecursiveCharacterTextSplitter.from_huggingface_tokenizer(
tokenizer=AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L12-v2"),
chunk_size=256,
chunk_overlap=32,
strip_whitespace=True,
)
docs = text_splitter.split_documents(pages)
This approach ensures that we maintain the integrity of paragraphs and sentences while splitting the text.
Vector Database
Next, we will establish a vector database to store our encoded document chunks. For this, we will use the Faiss library, which is optimized for similarity searches.
!pip install faiss-cpu
from langchain.vectorstores import FAISS
from langchain_community.vectorstores.utils import DistanceStrategy
faiss_db = FAISS.from_documents(docs, encoder, distance_strategy=DistanceStrategy.COSINE)
This database allows us to query and retrieve the most relevant document segments based on user queries.
User Interface with Streamlit
Finally, we will integrate everything into a user-friendly interface using Streamlit.
!pip install streamlit
import os
import streamlit as st
from model import ChatModel
import rag_util
FILES_DIR = os.path.normpath(os.path.join(os.path.dirname(os.path.abspath(__file__)), "..", "files"))
st.title("LLM Chatbot RAG Assistant")
@st.cache_resource
def load_model():
return ChatModel(model_id="google/gemma-2b-it", device="cuda")
@st.cache_resource
def load_encoder():
return rag_util.Encoder(model_name="sentence-transformers/all-MiniLM-L12-v2", device="cpu")
model = load_model()
encoder = load_encoder()
def save_file(uploaded_file):
file_path = os.path.join(FILES_DIR, uploaded_file.name)
with open(file_path, "wb") as f:
f.write(uploaded_file.getbuffer())return file_path
with st.sidebar:
max_new_tokens = st.number_input("max_new_tokens", 128, 4096, 512)
k = st.number_input("k", 1, 10, 3)
uploaded_files = st.file_uploader("Upload PDFs for context", type=["PDF", "pdf"], accept_multiple_files=True)
file_paths = [save_file(uploaded_file) for uploaded_file in uploaded_files if uploaded_file is not None]
if uploaded_files:
docs = rag_util.load_and_split_pdfs(file_paths)
DB = rag_util.FaissDb(docs=docs, embedding_function=encoder.embedding_function)
if "messages" not in st.session_state:
st.session_state.messages = []
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
if prompt := st.chat_input("Ask me anything!"):
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
user_prompt = st.session_state.messages[-1]["content"]
context = None if not uploaded_files else DB.similarity_search(user_prompt, k=k)
answer = model.generate(user_prompt, context=context, max_new_tokens=max_new_tokens)
response = st.write(answer)
st.session_state.messages.append({"role": "assistant", "content": answer})
You can find the complete code on my GitHub. Clone the repository and run the application using:
streamlit run llm-chatbot-rag/src/app.py
A Real-World Application: Chat with a PDF User Manual
RAG techniques can significantly enhance customer support by allowing users to extract information from lengthy PDF manuals. For instance, I tested our RAG LLM chatbot using a 204-page user manual for a Samsung washing machine. The chatbot effectively retrieved relevant troubleshooting information when queried.

Conclusion
RAG represents a groundbreaking approach that empowers LLMs with external knowledge. While LLMs excel at general knowledge compression, RAG enables them to access domain-specific information. The fundamental concept involves utilizing a retriever component to source relevant data and a generator component to formulate responses.
In this tutorial, we meticulously constructed a RAG pipeline and demonstrated its application with a PDF user manual. The future holds exciting possibilities where household appliances could interact with LLMs, providing immediate assistance based on their manuals.
References
[1] P. Lewis et al. (2021), Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, arXiv:2005.11401
[2] N. Muennighoff, et al. (2023), MTEB: Massive Text Embedding Benchmark, arXiv:2210.07316
Programming Resources
The second video showcases how to build a RAG application that can query information from a PDF using Llama2.