Data Drift: Understanding Its Sources and Implications
Written on
Introduction to Data Drift
The phenomenon of data drift can manifest in numerous ways, often taking on various visual forms.
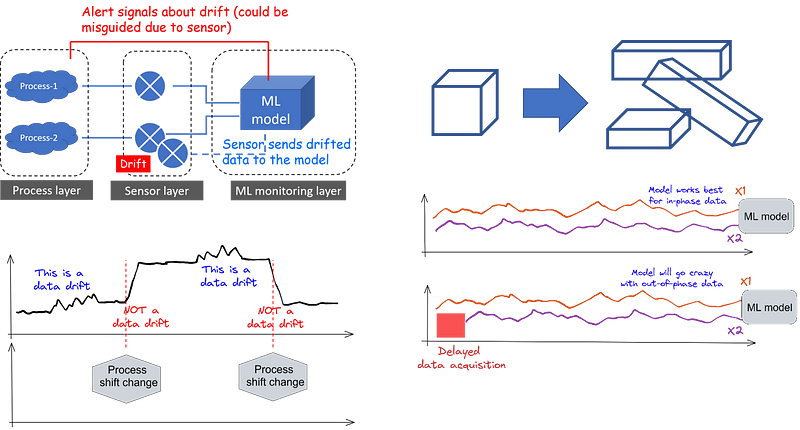
Data drift is critical to consider in the realm of machine learning (ML). Current ML models primarily serve as advanced inductive systems, aiming to extrapolate from a limited dataset to broader generalizations. For these models to function effectively, they rely on a key premise: the distribution of input data must remain relatively stable over time. If data drift occurs, the model's ability to generalize may become compromised, leading to a gradual decline in performance as it adapts to data that diverges from its training set.
Thus, it's essential to implement monitoring and timely detection of data drift within MLOps or ModelOps workflows to ensure the ongoing success of ML model deployments. Additionally, understanding data drift is crucial for the field of Explainable AI (xAI).
Section 1.1: Data Drift Monitoring in MLOps
A comprehensive overview of where data drift monitoring fits within the MLOps lifecycle can be found in the following resource:
Detecting Data Drift: Techniques and Examples
Many discussions about data drift focus on the shapes and statistical characteristics of input distributions. Here, we will explore examples of data streams feeding ML models in the form of time series, illustrating variations to clarify the concept. We will also examine both obvious and subtle sources of data drift within an industrial context.
Section 1.2: Obvious Examples of Data Drift
Data drift can be likened to a box of chocolates—you never know what to expect next! Let's dive into some clear-cut and less apparent examples.
Level Shift
This is a straightforward type of data drift, often identified as an ‘outlier’ or ‘anomaly’ in unsupervised model contexts. It's important to note that such drift may be temporary, necessitating quick identification of both its onset and conclusion.

Variance Shift
This form of drift is subtler and more challenging to detect.

Decrease in Variance
While high variance is often considered undesirable, a sudden decrease in variance can also indicate a data drift, reflecting changes in distribution properties.

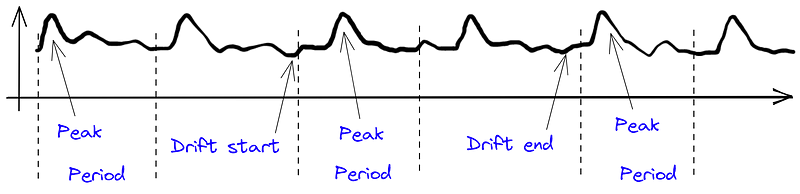
Peak Shifts Within Periods
This type of drift can be more elusive. Data often follows a periodic pattern with identifiable peaks. If the position of a peak shifts within its cycle, it may indicate a drift that simple statistical methods might overlook.
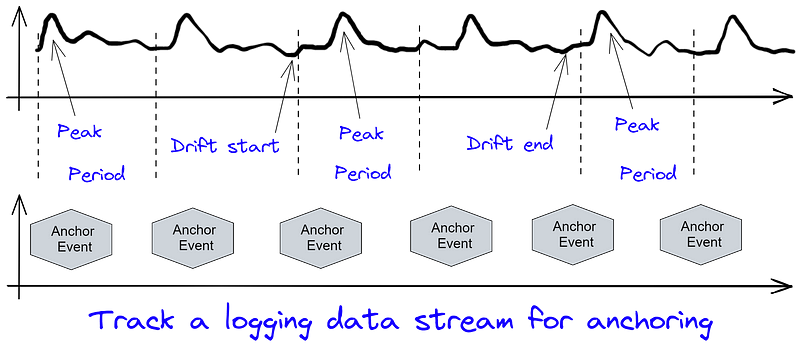
Contextual Data Monitoring
Monitoring a logging stream with fixed-time indicators, such as a shift's start or a machine reset, can help detect these temporal shifts intuitively. Effective data monitoring must ensure precise time synchronization.
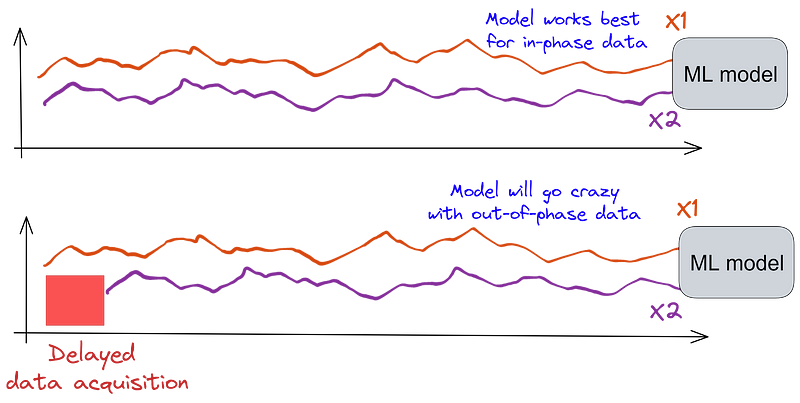
Phase Shifts and Delays
Phase shifts can severely impact ML models that utilize time-series data, potentially leading to incorrect predictions. If data streams become unsynchronized, the model's predictions may become erroneous.
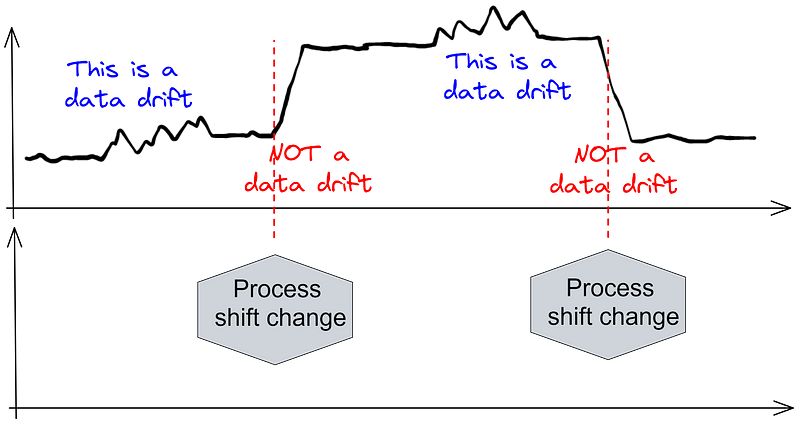
Distinguishing Drift from Non-Drift
In industrial contexts, changes in process recipes and settings can occur frequently. Monitoring this contextual data is crucial for accurately identifying data drift.
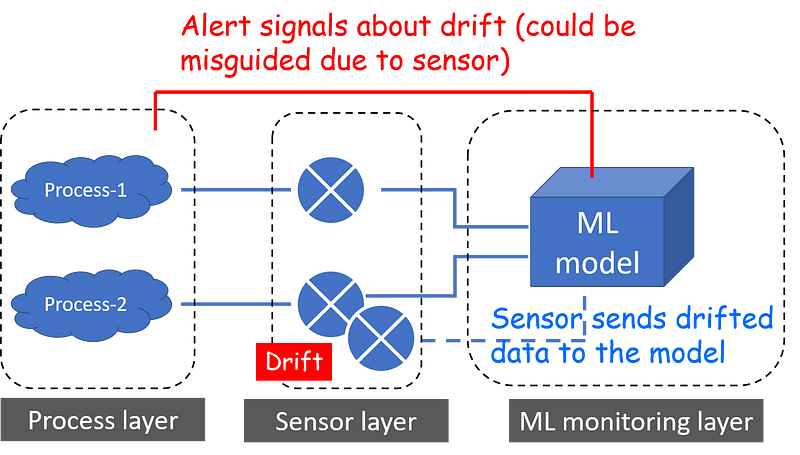
Measurement and Sensor Drift
Sensor drift is particularly challenging to detect. Although input data streams may be accurate, the sensors measuring this data may drift, leading to misinterpretations and erroneous recommendations.
Conclusion
In this article, we delved into the concept of data drift through visual examples, highlighting the complexities involved in detecting and analyzing it, even in simple cases. Techniques such as signal processing and contextual data integration may be necessary to accurately identify data drift's onset and nature.
Mitigating data drift is not a one-size-fits-all solution; strategies will vary depending on the specific industry and application. For a more systematic exploration of potential mitigations, consider reading the following resource:
“My data drifted. What’s next?” How to handle ML model drift in production.