Understanding and Implementing Quantization in Large Language Models
Written on
Chapter 1: Introduction to Quantization
Recent advancements have made it feasible to deploy and fine-tune large language models (LLMs) containing billions of parameters on everyday hardware, including personal laptops.

The rise of Large Language Models (LLMs) has been significant, especially with the latest iterations of ChatGPT/GPT-4 and new open-source models such as Llama2. However, the memory requirements for these models are substantial. For instance, to store a model with 10 billion parameters, you would need approximately 40 GB of memory, assuming each parameter is represented as a 32-bit float. In comparison, a 1 billion parameter model requires around 4 GB, while a 100 billion parameter model necessitates 100 GB. To achieve rapid inference speeds, these models typically need to reside in RAM or, better yet, in GPU memory, leading to high deployment costs.
Section 1.1: Floating Point Arithmetic and Quantization
Quantization presents a solution to this memory challenge by converting a 32-bit model to a lower precision format, such as 8-bit or 4-bit, effectively reducing memory usage. An 8-bit model would consume four times less memory, making it far more feasible to run smaller models locally on standard consumer CPUs or GPUs.
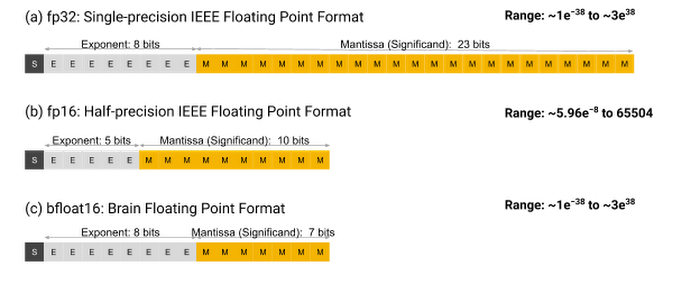
For a deeper understanding of floating point precision, refer to the image below. Here, you can see that FP32 comprises 32 bits, which is double that of FP16.
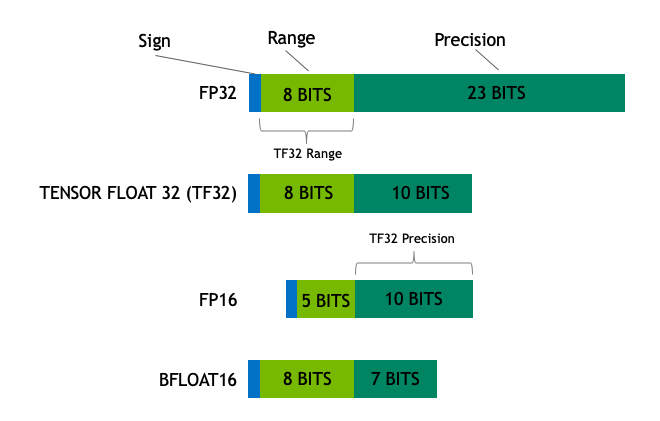
Training a machine learning model using bfloat16 can cut memory usage in half; however, this format sometimes struggles due to its limited range. This can lead to performance issues as model weights may fall outside the acceptable range during training. Nevertheless, innovations in floating-point precision, such as BF16 and TF32 formats, have emerged to address these challenges. The bfloat16 format, for example, maintains the same range as fp32 but sacrifices some precision. Researchers have demonstrated that models trained with bfloat16 can perform nearly as well as those trained with fp32.
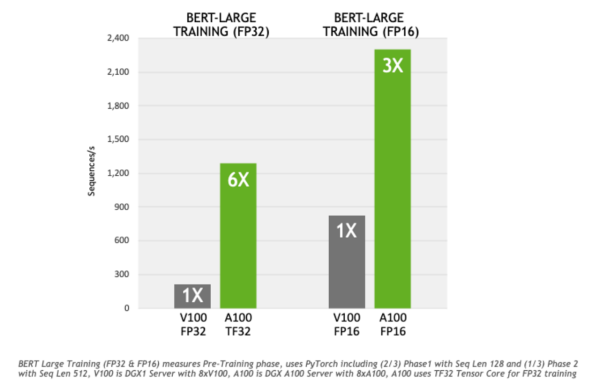
NVIDIA's introduction of the tf32 format has led to significant improvements, resulting in a sixfold increase in the training speed of models like BERT.
Section 1.2: Model Quantization Techniques
While the aforementioned concepts apply to model parameters during the training phase, there are additional quantization strategies, including post-training quantization and quantization-aware training. The groundbreaking research presented in the GPTQ paper focused on information reduction during quantization, successfully converting models to ~int4 and achieving nearly four times the memory savings by minimizing the mean squared error between the model and its quantized counterpart, layer by layer.
Additionally, the bitsandbytes package simplifies quantization for Hugging Face transformer models. However, it has been observed that bitsandbytes quantized models may have slightly slower inference times compared to those quantized with GPTQ.
Chapter 2: Running Quantized LLMs Locally
Two main developments have led to the surge of desktop applications like LM Studio, which allow users to download and run models locally. First, model quantization enables the download of a 7 billion parameter model, which, when quantized to 4 bits, requires only about 3-4 GB of memory—suitable for RAM or GPU memory for efficient inference. Second, the ggml library, a C/C++ port for LLMs, has simplified the loading of these models across various operating systems. GGML’s approach to quantization is less complex than GPTQ, as it simply rounds weights to lower precision. TheBloke, a notable contributor on Hugging Face, has added over 350 fine-tuned and quantized ggml models to the Hugging Face model hub, allowing easy integration into popular LLM desktop applications like LM Studio.
Deep Dive: Quantizing Large Language Models, part 1 - YouTube
This video explores the quantization process for large language models, highlighting key techniques and innovations.
Section 2.1: Fine-Tuning and Quantization
While it’s not possible to conduct full training on quantized models, parameter-efficient fine-tuning can be achieved using Low Rank Adapters (LoRA). This method allows for the adjustment of adapters without needing to fine-tune the entire model. The typical workflow involves taking an existing pre-trained LLM, quantizing it using GPTQ or bitsandbytes, and then fine-tuning it with QLORA, where "Q" denotes quantized.
Section 2.2: Key Takeaways and Future Directions
From an architectural standpoint, quantization is a sensible approach, as it reduces memory requirements and facilitates easier, more cost-effective deployment and fine-tuning. However, it is crucial to minimize any degradation in response quality for quantized models. Although quantizing reduces the precision of weights, experiments from Hugging Face have indicated that GPTQ and bitsandbytes quantized models maintain acceptable performance during inference. The efficacy of ggml quantized models, however, remains largely untested.
As we face GPU shortages and significant hardware constraints for deploying models with 10 to 100 billion parameters, quantization and quantized fine-tuning strategies present promising solutions. There has been an explosion of LLM desktop applications leveraging these quantized models, enabling them to run locally on standard laptops. However, assessing the response quality of these smaller models in specialized domains poses a different challenge altogether.
Exciting developments lie ahead!
How to quantize Large Language Models - YouTube
This video provides insights into the quantization process of large language models, detailing methods and best practices.
References:
- Introduction to Quantization cooked in ? with ???? (huggingface.co)
- LM Studio — Discover, download, and run local LLMs
- GitHub — ggerganov/ggml: Tensor library for machine learning
- TheBloke (Tom Jobbins) (huggingface.co)
Thank you for engaging with our community! If you found this content valuable, please consider following me for more insights on generative AI and its applications in the real world.